The Cost of Being Human-Friendly: Python

2026-01-13
Python is the most commonly recommended language for people starting programming.
At the same time, there is always that line that follows it around:
“Starting with Python can actually be poison.”
For a long time, I didn’t understand what that meant.
Python was intuitive.
Easy to read.
It let you see results quickly.
It was a perfectly good language.
But recently, while solving coding test problems, I felt something off for the first time.
In the process of improving my code, I chose a method that was clearly more efficient algorithmically—
and yet the result was the opposite of what I expected.
It has been about a year and a half since I started programming, and during that time I believed Python was easy.
Unlike “uncomfortable” C or Java, Python had syntax that felt close to natural language, and it seemed like you could build anything like magic.
But the truth is: there was no magic.
Someone was paying the bill the whole time—without me noticing.
Who was it? CPython? No.
It was me.
Every generator I’d been using out of habit.
Every for loop.
Every piece of code that “just worked.”
Behind those, frames were created, boundaries were crossed, and overhead piled up.
I didn’t know.
I didn’t know Python was designed so you wouldn’t have to be aware of these costs.
This post is a record of chasing that discomfort all the way down, and what I found:
the price Python pays for being “human-friendly.”
Problem Setup
A simple tiered discount rule based on price:
- ≥ 100,000 KRW → 5% discount
- ≥ 300,000 KRW → 10% discount
- ≥ 500,000 KRW → 20% discount
At first, I solved it using nested ternary expressions.
def solution(price):
return price * 0.8 if price >= 500_000 else price * 0.9 if price >= 300_000 else price * 0.95 if price >= 100_000 else price
It works correctly.
But the problem is obvious: complexity grows every time you add a condition, and readability is basically at the floor.
First Improvement: Boolean Indexing
So I looked for another approach.
def solution(price):
return price * (100, 95, 90, 80)[(price >= 100_000) + (price >= 300_000) + (price >= 500_000)] // 100
This works like this:
You compute the sum of cond_1 + cond_2 + cond_3 using boolean expressions (so it becomes 0–3),
then use that sum directly as an index into a tuple of discount rates.
From a teamwork perspective, it is dangerously close to “magic code.”
But compared to nested ternaries, it’s clean—and it seems more extensible.
Second Improvement: An “Optimization” Attempt — next() + Generator
Then a question hit me:
“If
priceis ≥ 500,000, then
(True) + (True) + (True) = 3,
so why do all three comparisons?
Wouldn’t it be faster to check in reverse order and stop at the first match?”
Algorithmically, that is obviously reasonable.
Reducing the average number of comparisons should be more efficient.
So I tried short-circuiting.
def solution(price):
rate = next(r for p, r in ((500_000, 0.8), (300_000, 0.9), (100_000, 0.95), (0, 1)) if price >= p)
return int(price * rate)
- If
priceis ≥ 500,000, it stops on the first comparison - Average number of comparisons decreases
- From an algorithmic perspective, this is “efficient”
In theory, it looked the most convincing. Almost perfect.
But in reality, it ran slower than both the ternary version and boolean indexing.
So I measured it with timeit.
Measured Results
They say life never goes the way you want.
Below is not the full table, but only representative points where the “personality” of each approach starts to diverge.
(Unit: µs / call, median)
Environment
- Python 3.12.10
- macOS 15.5 (Apple Silicon / M3 Pro)
- timeit iterations: 500,000 ~ 1,000,000
| Branch count | Boolean ops (C level) | next + generator (Python level) |
Result |
|---|---|---|---|
| 3 | 0.059 µs | 0.257 µs | Boolean is ~4.3× faster |
| 5 | 0.076 µs | 0.119 µs | Boolean still wins (~1.6×) |
| 10 | 0.122 µs | 0.119 µs | Nearly equal |
| 20 | 0.219 µs | 0.124 µs | next is ~1.8× faster |
| 30 | 0.312 µs | 0.120 µs | next is ~2.6× faster |
In a typical coding test problem with 3 branches,
next + generator was 4.3× slower.
The gap starts shrinking around 5–10 branches,
and beyond 10 branches, next() becomes favorable.
But here’s the irony:
If you have 10+ branches, you probably shouldn’t be doing sequential next() scanning in the first place.
At that point, structures like binary search (bisect) or dictionaries often win.
If you actually measure it:
| Branch count | next() |
bisect |
dict |
Result |
|---|---|---|---|---|
| 10 | 0.027s | 0.005s | 0.006s | bisect is ~5.4× faster |
| 20 | 0.027s | 0.006s | 0.006s | bisect is ~4.5× faster |
| 30 | 0.031s | 0.006s | 0.007s | bisect is ~5× faster |
| 50 | 0.049s | 0.006s | 0.007s | bisect is ~8.3× faster |
So the range where next() starts beating boolean (10+ branches) is already the range where you should be using bisect or dict.
In other words:
A “do fewer comparisons” optimization ends up slower—
because the overhead you add to implement it costs more than the comparisons you saved.
So Is Short-Circuiting Always Inefficient in Python?
No.
As shown above, it is inefficient when you pull in high-level abstractions just to manufacture short-circuiting.
But there are cases where short-circuiting in Python is natural and actually efficient.
Here is a snippet from code I submitted to a company’s coding test.
for other_start, other_end in self.events.values():
if not (end_min <= other_start or start_min >= other_end):
return None
This checks whether a schedule overlaps:
end_min <= other_start→ the new event ends completely before the existing event startsstart_min >= other_end→ the new event starts completely after the existing event ends
If either is true, they do not overlap.
If neither is true, they overlap.
Why is this short-circuit actually efficient?
Because or here is language-level short-circuit evaluation.
- If the left side is
True, Python does not evaluate the right side - No generator
- No frame creation
- No extra abstraction overhead
In other words: you reduce condition checks without sacrificing anything.
This is fundamentally different from next + generator.
This example implies:
- The issue is not short-circuit itself
- The issue starts when you insert high-level abstractions just to “implement” short-circuiting
- Language-level short-circuiting (
and,or) is natural and basically free
Behind the “Magic”: The Cost Python Hid
Why is next + generator slow?
Up to now, I had learned:
- comprehensions are better than
forloops - generators are even better than comprehensions
And I did not doubt it much.
Especially in coding tests—where you return once and never reuse data—
generators felt like pure “magic.”
But the problem was that I never checked the subject of the word “efficient.”
Generators are efficient for memory, not for speed.
While I was proud of myself for “cutting comparisons and writing smarter code,”
this is what was happening behind the scenes:
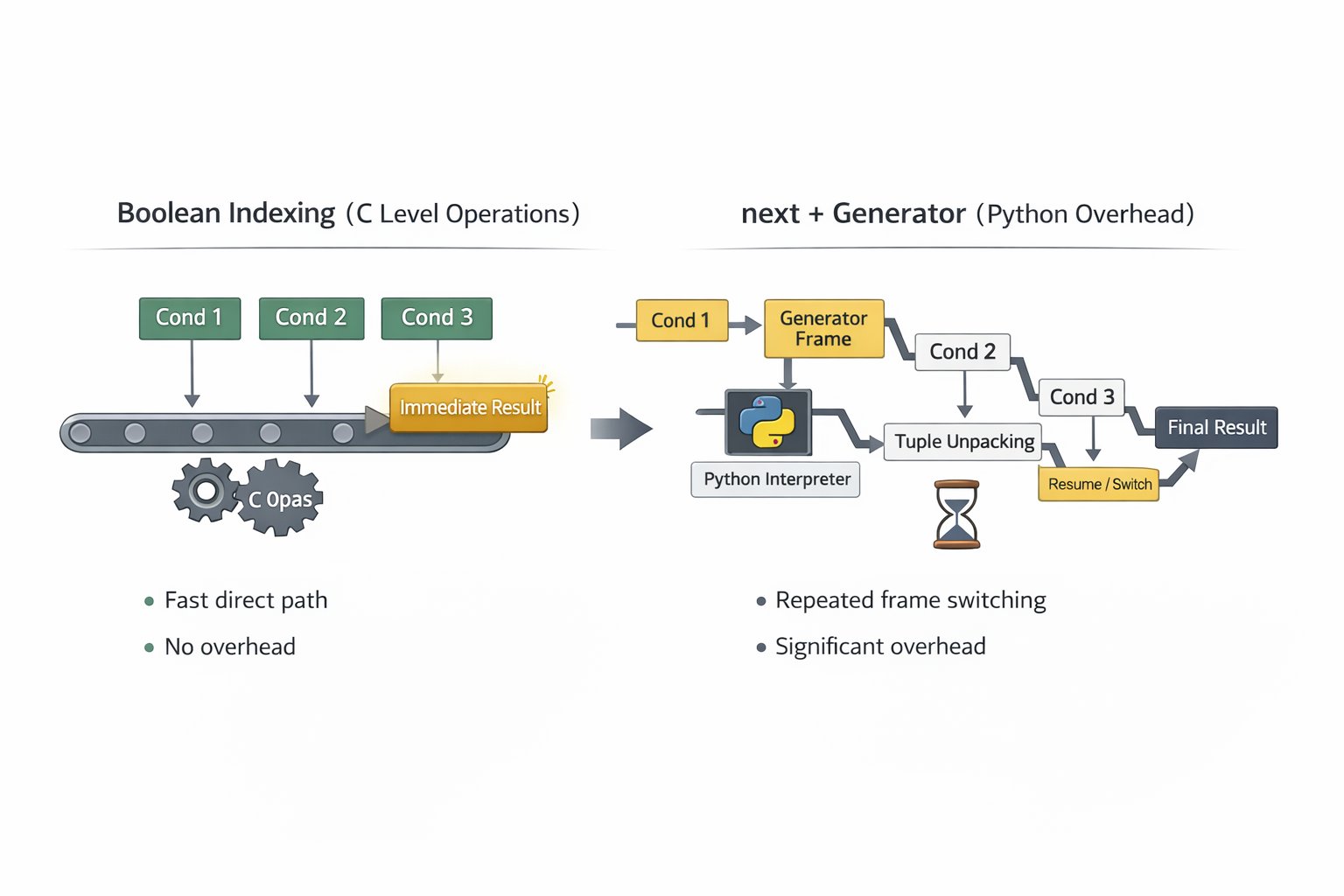
- Create a generator object
- Create and maintain a generator frame
- Call
next() - Enter the iterator protocol (crossing the C ↔ Python boundary)
- Tuple access and unpacking
- Evaluate the condition (including dynamic type checks)
- On failure, resume the generator
- Repeat suspend/resume of the frame
So I was adding a large amount of Python-level overhead
just to save a few comparisons.
Meanwhile, boolean indexing?
It still performs all comparisons,
but most of the path is a straight line of simple C-level operations.
- No frame creation
- No boundary ping-pong
- No generator overhead
- Minimal interpreter involvement
The Truth Behind “It Just Works”
result = next(generator)
One line. Simple and intuitive.
But the truth is:
I wrote “one line,” but Python executed dozens of steps where I couldn’t see them.
And I did not realize that for a year and a half.
Why didn’t I notice?
Python’s design philosophy:
“Python is designed to be easy to learn and easy to read.”
— Guido van Rossum
The hidden meaning:
easy to learn = hide complexity
easy to read = hide cost
But do not misunderstand:
This is not a bug. It is intentional.
Python intentionally hid:
- pointers
- memory management
- type checks
- frame management
- the cost itself
Why?
So that you don’t have to know.
This Is the “Poison” People Talk About
Beginner days:
x = [1, 2, 3]
for item in x:
print(item)
“It just works” → great. easy to learn.
Unlike alien-looking low-level languages, this is a high-level language, close to natural language.
I do not need to understand the internals.
Now:
result = next(complex_generator)
“It works, but why is it slow?” → the poison activates.
The poison is simply:
making decisions without knowing the cost.
I:
- wrote the code
- ran it
- got the result
But I had no idea:
- how many frames were created
- how many boundaries were crossed
- how much overhead was accumulated
I did not know,
and I did not even care.
What I Was Missing
What Python told me:
“I’m easy. My syntax is close to natural language. You can learn fast.”
That is not a lie. It is true.
But what Python did not say:
“In exchange, you’ll sacrifice performance.”
“CPython will do the work for you.”
“A bill will arrive one day.”
Strictly speaking, Python did not intend to deceive.
It just did not tell me because I never asked.
If I had to put it in a metaphor:
I got blinded by the looks.
int* ptr = malloc(sizeof(int) * 100);
if (ptr == NULL) {
}
for(int i = 0; i < 100; i++) {
ptr[i] = i;
}
free(ptr);
Not even joking: that still looks scary.
numbers = [i for i in range(100)]
How can you not fall in love with this?
“It’s easier than I expected.”
“The code looks sick.”
“This is what real programming should look like.”
But then I reread the contract.
Page 1
Python
1. It is easy.
2. It is readable.
3. It is productive.
4. You can learn fast.
...
Somewhere around page 17.5
(The appendix nobody reads)
- This language may charge the following costs:
1. Interpreter overhead
2. Dynamic type checking cost
3. Generator frame management cost
4. C <-> Python boundary crossing cost
5. Memory management abstraction cost
...
- These charges may arrive without notice.
- Costs may continue to be charged even when the user is not aware of them.

I signed after reading page one and staring at Python’s face.
I did not even think about reading page 17.5
Only after reading the contract to the end did I realize:
If you have to dig this deep to see behind the abstraction,
that is proof that the abstraction is built extremely well.
For a year and a half, I benefited from it:
- I wrote code without worrying about pointers
- I got results without managing memory
- I learned fast without being crushed by complexity
Python was intentionally designed this way:
- so beginners can start easily
- so they do not get overwhelmed
- but so you can dig deeper when you need to
And Python kept that design for 30 years.
Python didn’t fool me.
I just didn’t read the contract all the way through.
The Law of Abstraction
Joel Spolsky said:
“All non-trivial abstractions, to some degree, are leaky.”
— Joel Spolsky
Are leaky abstractions always bad?
No.
- No abstraction → hard to learn, low productivity
- Abstraction exists → massive productivity in most situations
But once you enter boundary zones—performance, precise resource control, etc.—
you eventually have to understand the hidden internals.
That is not failure. It is the natural result of trade-offs.
And this isn’t just Python.
For example:
React
- Gives: declarative UI, component reuse
- Hides: virtual DOM overhead, rerender costs
Docker
- Gives: isolation, deployment convenience
- Hides: network overhead, image bloat
So: no abstraction is free.
Understanding cost, grasping trade-offs, choosing based on context—
that is engineering.
What Python taught me this time wasn’t simply “Python is slow,”
but:
Every technology hides something.
Conclusion
When I started programming with Python,
I heard “it’s good for beginners, but it can be poison.”
Now I understand what that means.
The poison was:
- not knowing the cost
- not being able to see behind abstraction
- not being able to choose consciously
But if you flip it:
- you learn the costs
- you understand the abstraction
- you make deliberate choices
Then it can become medicine.
Python is still a great language.
It’s just that now I feel like I finally understand when and why to use it.
And that made me curious:
What does a language look like when it minimizes abstraction?
So I decided to study Rust alongside Python.
Because Rust exposes what Python hides:
- Ownership
- Borrowing
- Lifetime
- Zero-cost abstractions
It will be harder.
But I think I’ll be able to understand “why” more deeply.
I’ve tasted the poison.
Now it’s time to go make the medicine.