「人間に優しい」のコスト:Python

2026年01月13日
Pythonは、プログラミング入門者に一番よく勧められる言語だ。
同時に、入門で始めると逆に毒になる、という話もだいたいセットで付いてくる。
昔の自分は、その意味が分からなかった。
Pythonは直感的で、読みやすくて、結果もすぐ見える。
十分に良い言語だった。
ところが最近、コーディングテストの問題を解いていて、初めて違和感が出た。
コードを改善している過程で、アルゴリズム的には明らかに効率的な方法を選んだのに、結果が予想と違った。
プログラミングを始めてかれこれ1年半。
その間ずっと、自分はPythonは「簡単」だと信じていた。
「不便な」CやJavaと違って、自然言語に近い文法で何でも魔法みたいに作れる、そう思っていた。
でも、実際は魔法なんてなかった。
自分が知らない間に、誰かがずっとコストを支払っていた。
それが誰かって? CPython? 違う。
自分だった。
今まで惰性で使ってきたあらゆるgenerator、あらゆるfor文、あらゆる「ただ動いてた」コード。
その裏側でフレームが作られ、境界を往復し、オーバーヘッドが積もっていた。
自分は知らなかった。
Pythonは、こういうコストをユーザーがわざわざ意識しなくても済むように設計されている、ということを。
この記事は、その違和感を最後まで掘り下げて、Pythonの「人間に優しい」設計が支払っている代償にぶつかった記録だ。
問題状況
価格に応じて割引率を適用する、単純なティア分岐の問題。
- 10万円以上 → 5%割引
- 30万円以上 → 10%割引
- 50万円以上 → 20%割引
最初は三項演算子で解いた。
def solution(price):
return price * 0.8 if price >= 500_000 else price * 0.9 if price >= 300_000 else price * 0.95 if price >= 100_000 else price
ちゃんと動く。
ただ、条件が増えるたびに複雑度が上がるのと、可読性が床にめり込んでいくのが問題。
1つ目の改善:Booleanインデクシング
別の方法を探した。
def solution(price):
return price * (100, 95, 90, 80)[(price >= 100_000) + (price >= 300_000) + (price >= 500_000)] // 100
このコードはこう動く。
Boolean演算で cond_1 + cond_2 + cond_3 の合計(0〜3)を作って、その値をそのままタプルのインデックスに突っ込み、割引率を決める。
協業の視点だと「マジックコード」寄りだけど、三項よりはスッキリしていて、拡張もしやすそうに見える。
2つ目の改善:最適化(?)の試み — next() + generator
ここで疑問が湧いた。
priceが50万以上なら
(True) + (True) + (True) = 3 だ。
なのに、わざわざ3回全部比較する必要ある?
逆順にして、最初にマッチしたら終わらせる方が、理論的には速いはずじゃない?
アルゴリズム的には当然そう。平均比較回数を減らすのが効率的。
なので short-circuit を試した。
def solution(price):
rate = next(r for p, r in ((500_000, 0.8), (300_000, 0.9), (100_000, 0.95), (0, 1)) if price >= p)
return int(price * rate)
- priceが50万以上なら最初の比較で終了
- 平均比較回数は減る
- アルゴリズム観点では「効率的」
理論上は一番それっぽい。完璧に見えた。
でも実際には、三項やBooleanインデクシングより遅かった。
だから timeit で測った。
実測結果
人生って、だいたい思い通りにいかない。
以下はフルの表じゃなくて、性格が分かれる代表ポイントだけ抜粋。(単位:µs / call、中央値)
測定環境
- Python 3.12.10
- macOS 15.5(Apple Silicon / M3 Pro)
- timeit繰り返し:500,000〜1,000,000回
| 分岐数 | Boolean演算(C Level) | next + generator(Python Level) | 結果 |
|---|---|---|---|
| 3 | 0.059 µs | 0.257 µs | Booleanが約4.3倍速い |
| 5 | 0.076 µs | 0.119 µs | Booleanがまだ優勢(1.6倍) |
| 10 | 0.122 µs | 0.119 µs | ほぼ同等 |
| 20 | 0.219 µs | 0.124 µs | nextが1.8倍速い |
| 30 | 0.312 µs | 0.120 µs | nextが2.6倍速い |
分岐3つの、よくあるコーディングテスト規模では、
next + generatorが4.3倍遅かった。
差が縮み始めるのは分岐5〜10あたり。
10を超えると next() が勝ち始める。
でも皮肉なことに、分岐が10を超えるなら、
next()の逐次探索より 二分探索(bisect) や dict を考えた方がいい。
実際に測るとこうなる。
| 分岐数 | next() | bisect | dict | 結果 |
|---|---|---|---|---|
| 10 | 0.027s | 0.005s | 0.006s | bisectが5.4倍速い |
| 20 | 0.027s | 0.006s | 0.006s | bisectが4.5倍速い |
| 30 | 0.031s | 0.006s | 0.007s | bisectが5倍速い |
| 50 | 0.049s | 0.006s | 0.007s | bisectが8.3倍速い |
つまり、next()がbooleanを上回る領域(10以上)は、
そもそもbisectやdictを使うべき領域でもある。
「比較を減らす」最適化が、逆に遅くなる。
じゃあ、Pythonではshort-circuitは常に非効率なのか?
そうじゃない。
さっき見たように、short-circuitを「作るために」高レベル抽象を持ち込むと非効率になるだけ。
Pythonで short-circuit が自然に効いて、実際に効率的なケースもある。
これは自分が某社のコーディングテストに出したコードの一部。
for other_start, other_end in self.events.values():
if not (end_min <= other_start or start_min >= other_end):
return None
これは予定が重なるか判定するロジック。
end_min <= other_start→ 新イベントが既存イベントより完全に前で終わるstart_min >= other_end→ 新イベントが既存イベントより完全に後で始まる
どちらかが成り立てば 重ならない。両方ダメなら重なる。
なぜこのshort-circuitは本当に効率的なのか?
ここで使っている or は、Python言語仕様として提供されている 短絡評価(short-circuit evaluation) だから。
- 左が
Trueなら右は評価しない - ジェネレータなし
- フレーム生成なし
- 追加オーバーヘッドなし
つまり、何も犠牲にせず条件評価だけ減らせる。
さっきの next + generator とは性格が別物。
この例が言ってる結論はこう。
- Pythonで問題なのはshort-circuitそのものじゃない
- short-circuitを「実装するため」に高レベル抽象を挟んだ瞬間が問題
and/orのような言語レベル短絡は自然で、損がない
「魔法」の裏側:Pythonが隠したコスト
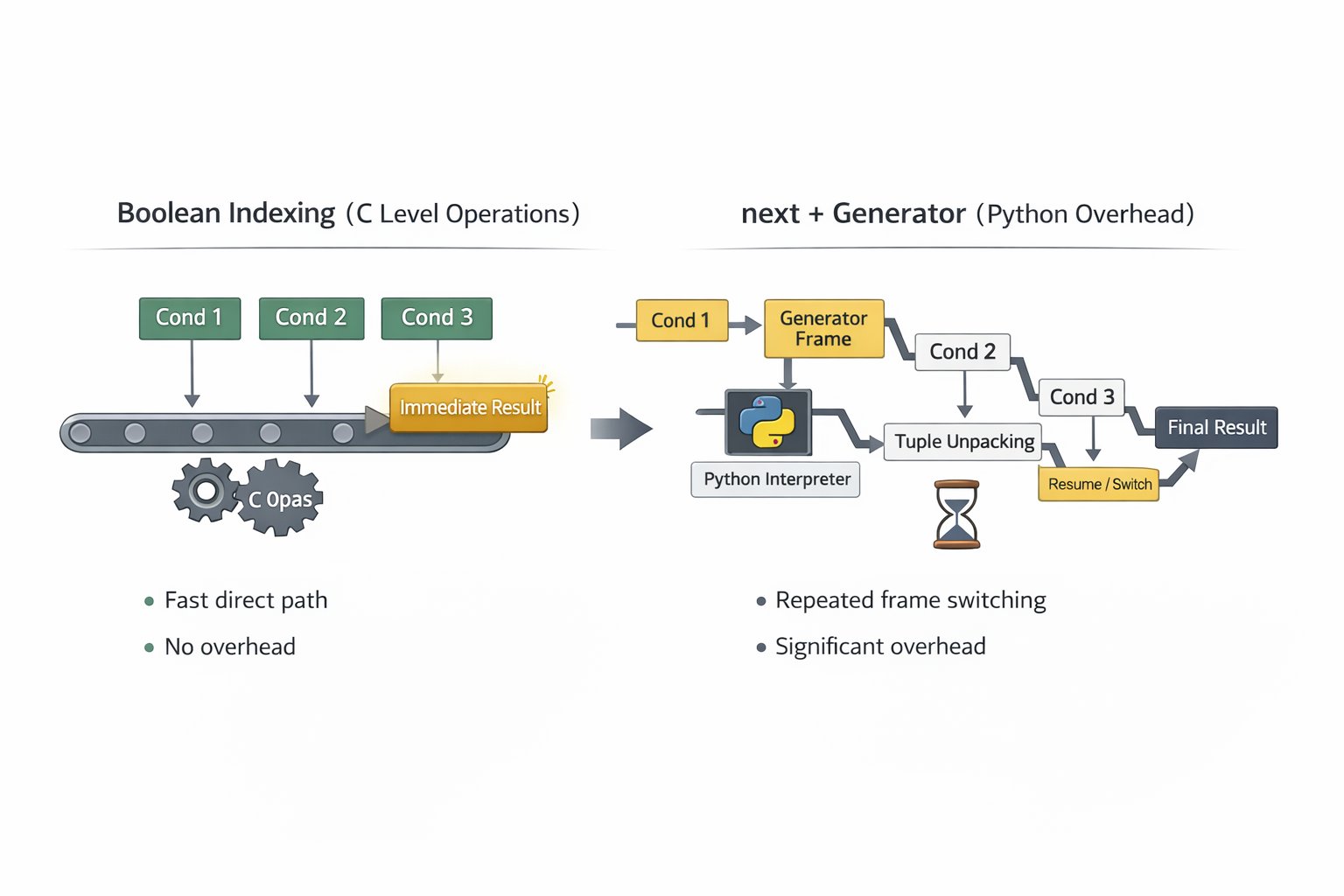
next + generator はなぜ遅いのか?
自分は今まで、データを回したりリストを作るとき、
forより内包表記、内包表記よりジェネレータが効率的だと教わってきたし、特に疑ってこなかった。
特に「コーディングテスト」みたいに、一回返して終わりで再利用もしない環境なら、
ジェネレータはむしろ「魔法」だと思い込んでいた。
でも問題は、「効率」という言葉の主語を確認してなかったこと。
ジェネレータが効率的なのはメモリであって、速度じゃない。
「比較回数を減らして賢く書いた」と気持ちよくなっていたその瞬間、裏ではこういうことが起きていた。
- ジェネレータオブジェクト生成
- ジェネレータフレーム生成・維持
next()呼び出し- イテレータプロトコル突入(C ↔ Python の境界)
- タプルアクセスとアンパック
- 条件式評価(動的型チェック含む)
- 失敗時にジェネレータ再開(resume)
- suspend/resume の反復
つまり、比較を数回減らすために、Pythonレベルのオーバーヘッドを大量に追加していたという話。
じゃあBooleanインデクシングは?
比較自体は最後までやる。
でも経路の大半が Cレベルの単純演算 で、いわば 直線ルート。
- フレーム生成なし
- 境界往復なし
- ジェネレータオーバーヘッドなし
- インタプリタの介入が最小
「ただ動く」の正体
result = next(generator)
たった一行。分かりやすい。
でも 自分は一行を書いただけで、Pythonは見えない場所で数十ステップ動いていた。
それを1年半、知らなかった。
なぜ知らなかったのか?
Pythonの設計思想はこう。
"Python is designed to be easy to learn and easy to read."
— Guido van Rossum
ここに隠れてる意味はこう。
easy to learn= 複雑さを隠すeasy to read= コストを隠す
ただし誤解しないでほしい。
これはバグじゃなくて、意図された設計だ。
Pythonは意図的に、
- ポインタを隠した
- メモリ管理を隠した
- 型チェックを隠した
- フレーム管理を隠した
- そのコストを隠した
なぜ?
お前が知らなくて済むように。
最初に言ってた「毒」の正体
初心者のころはこう。
x = [1, 2, 3]
for item in x:
print(item)
「ただ動く」→ 良い。学びやすい。
外宇宙語みたいな低レベル言語と違って、自然言語っぽいし、原理を理解しなくても進める。
でも今はこう。
result = next(complex_generator)
「動くけど、なんで遅い?」→ ここで毒が発現する。
毒の正体はこれ。
コストを知らないまま意思決定する状態そのもの。
自分は
- コードを書いた
- 実行した
- 結果を得た
でもその過程で
- どれだけフレームが生成されたか
- どれだけ境界を越えたか
- どれだけオーバーヘッドが積もったか
何も知らなかったし、興味すらなかった。
自分が見落としていたこと
Pythonが言ったこと。
「簡単だよ。文法も自然言語に近いよ。すぐ学べるよ。」
これは嘘じゃない。事実。
ただ、
「その代わり性能は捨てるよ。」
「CPythonが代わりにやってやるよ。」
「いつか請求書が来るよ。」
これは言わなかった。
厳密には、自分が聞かなかっただけで、騙す意図があったわけでもない。
たとえるなら、単に顔に惚れた、みたいな話。
int* ptr = malloc(sizeof(int) * 100);
if (ptr == NULL) {
}
for(int i = 0; i < 100; i++) {
ptr[i] = i;
}
free(ptr);
冗談じゃなく、今見ても怖い。
numbers = [i for i in range(100)]
こんなの見せられて、どうやって好きにならずにいられる?
「思ったより簡単じゃん?」
「コードの見た目かっこいいじゃん?」
「これが“ちゃんとしたプログラミング”だろ!」
でも正気に戻って契約書を読み返すと、こうなってた。
1ページ
Python
1. 簡単です。
2. 読みやすいです。
3. 生産性が高いです。
4. すぐ学べます。
...
たぶん18ページあたり
- 本言語は次のコストを請求する場合があります。
1. インタプリタのオーバーヘッド
2. 動的型チェックのコスト
3. ジェネレータフレーム管理コスト
4. C <-> Python 境界往復コスト
5. メモリ管理の抽象化コスト
...
- 請求時期は予告なく到来する場合があります。
- 本コストは、ユーザーが認知していない状態でも継続的に請求されます。

自分は1ページ目とPythonの顔だけ見てサインした。
18ページは読む気すらなかった。
契約書を最後まで読んで初めて気づいた。
ここまで掘らないと抽象化の裏側が見えないってことは、
逆に言えば、その抽象化が めちゃくちゃ堅牢に設計されている ってことじゃないか?
自分は1年半、その恩恵を受けた。
- ポインタを気にせずコードを書けた
- メモリ管理なしで結果を出せた
- 複雑度を気にせず素早く学べた
Pythonは意図的にそう設計された言語だった。
- 初心者が始めやすいように
- 複雑さに潰されないように
- でも必要なら掘れるように
そしてその設計を30年維持してきた。
Pythonは自分を騙していない。
自分が契約書を最後まで読まなかっただけ。
抽象化の法則
Joel Spolskyはこう言った。
"All non-trivial abstractions, to some degree, are leaky."
(すべての“非自明な”抽象化は、程度の差はあれ漏れる)
漏れる抽象化は無条件で悪か?
違う。
- 抽象化がゼロ → 学びにくいし生産性も低い
- 抽象化がある → ほとんどの場面で圧倒的に生産性が高い
ただし境界領域(性能、厳密な資源制御など)に入ると、
隠していた内部を結局理解しないといけない。
それは失敗じゃなくて、トレードオフの自然な帰結。
そしてこれはPythonに限らない。
たとえば
React
- くれるもの:宣言的UI、コンポーネント再利用
- 隠すもの:Virtual DOMのオーバーヘッド、再レンダリングコスト
Docker
- くれるもの:環境隔離、デプロイの楽さ
- 隠すもの:ネットワークオーバーヘッド、イメージサイズ
つまり、どんな抽象化もタダじゃない。
コストを理解して、トレードオフを把握して、状況に合わせて選ぶ。
これがエンジニアリングだと思う。
Pythonが今回自分に教えたのは、単に「Pythonは遅い」じゃない。
「すべての技術は、何かを隠している」 ということだった。
結論
Pythonでプログラミングを始めるとき、
「入門には良いけど、毒になることがある」と聞いた。
今なら意味が分かる。
毒はこれだった。
- コストを知らない状態
- 抽象化の裏側が見えない状態
- 選べない状態
でも裏返せば
- コストを知って
- 抽象化を理解して
- 意識的に選ぶ
それは薬にもなる。
Pythonは今でも良い言語だ。
ただ、いつ、なぜ使うべきかが少し分かってきただけ。
だから気になった。
抽象化を最小化した言語って、どんな姿なんだろう?
次はRustをPythonと並行して学ぶことにした。
Pythonが隠していたものを、Rustは前に出してくるから。
- Ownership
- Borrowing
- Lifetime
- Zero-cost abstractions
難しくなるだろうけど、
「なぜ」をもっと深く理解できそうだ。
毒を経験した。
次は薬を作りに行く番だ。