'인간 친화'의 비용 : 파이썬

2026년 01월 13일
파이썬은 프로그래밍 입문자에게 가장 많이 추천되는 언어다.
동시에, 입문으로 시작하면 오히려 독이 될 수 있다는 말도 늘 따라붙는다.
과거의 나는 그 말을 이해하지 못했다.
파이썬은 직관적이고, 읽기 쉽고, 빠르게 결과를 확인할 수 있었다.
충분히 좋은 언어였다.
그런데 최근, 코딩 테스트 문제를 풀다가 처음으로 위화감이 들었다.
코드를 개선하는 과정 중에서 알고리즘적으로는 분명 더 효율적인 방법임에도 불구하고 예상과는 다른 결과가 나왔다.
프로그래밍을 시작한 지 어언 1년 반, 그동안 나는 파이썬이 쉽다고 믿었다.
'불편한' C나 Java와는 다르게 자연어와 가까운 문법으로 뭐든지 마법처럼 만들 수 있었다.
그런데 사실 마법은 없었다.
내가 모르는 사이 누군가 계속 비용을 치르고 있었다.
그게 누구냐고? CPython? 아니다.
나였다.
내가 지금까지 관성적으로 써 온 모든 generator, 모든 for문, 모든 '그냥 작동했던' 코드들.
그 뒤에서 프레임이 생성되고, 경계를 넘나들며 오버헤드가 쌓이고 있었다.
나는 몰랐다.
파이썬은 이런 비용을 사용자가 굳이 의식하지 않아도 되도록 설계되었다는 걸.
이 글은 그 위화감을 끝까지 파고들며 마주한 파이썬의 '인간 친화'가 치르는 대가에 대한 기록이다.
문제 상황
가격에 따라 할인율을 적용하는 단순한 티어 분기 문제다.
- 10만 원 이상 -> 5% 할인
- 30만 원 이상 -> 10% 할인
- 50만 원 이상 -> 20% 할인
처음엔 삼항 연산자를 이용해서 풀어봤다.
def solution(price):
return price * 0.8 if price >= 500_000 else price * 0.9 if price >= 300_000 else price * 0.95 if price >= 100_000 else price
정상적으로 동작한다. 다만 조건이 추가될 때마다 복잡도가 증가한다는 점과 바닥에 가까운 가독성이 문제다.
첫 번째 개선 : Boolean 인덱싱
그래서 다른 방법을 찾아봤다.
def solution(price):
return price * (100, 95, 90, 80)[(price >= 100_000) + (price >= 300_000) + (price >= 500_000)] // 100
이 코드는 다음과 같이 동작한다.
Boolean 연산으로 cond_1 + cond_2 + cond_3의 합을 구하고(0~3), 그 값을 그대로 튜플 인덱스에 넣어서 지정된 할인율을 적용시키는 로직이다.
협업 관점에서는 '매직 코드'에 가까운 코드지만 삼항에 비하면 깔끔하고 확장성도 좋아 보인다.
두 번째 개선 : 최적화(?) 시도 - next() + generator
그런데 문득 의문이 들었다.
'price가 50만 이상인 경우에
(True) + (True) + (True) = 3인데,
굳이 세 번 다 비교할 필요가 있나?
역순으로 첫 조건에서 매칭되면 바로 끝내는 게 이론적으로 더 빠르지 않나?'
알고리즘적으로는 당연히 그렇다. 평균 비교 횟수를 줄이는 게 더 효율적이니까.
그래서 short-circuit을 시도해봤다.
def solution(price):
rate = next(r for p, r in ((500_000, 0.8), (300_000, 0.9), (100_000, 0.95), (0, 1)) if price >= p)
return int(price * rate)
price가 50만 원 이상일 경우, 첫 비교에서 종료- 평균 비교 횟수 감소
- 알고리즘 관점에서는 "효율적"
이론적으로는 가장 그럴듯해 보이고, 완벽해 보였다.
그런데 실제로는 위의 삼항이나 Boolean 인덱싱에 비해서 실행 시간이 더 길었다.
그래서 timeit으로 측정해봤다.
실측 결과
원래 인생은 원하는 대로 흘러가지 않는다고 했던가?
아래는 전체 표가 아닌, 성향이 갈리는 대표적인 지점의 실측 값만 정리한 표다. (단위: µs / call, 중앙값 기준)
측정 환경
- Python 3.12.10
- macOS 15.5(Apple Silicon / M3 Pro)
- timeit 반복: 500,000 ~ 1,000,000회
| 분기 수 | 불리언 연산 (C Level) | next + generator (Python Level) | 결과 |
|---|---|---|---|
| 3개 | 0.059 µs | 0.257 µs | 불리언이 약 4.3배 빠름 |
| 5개 | 0.076 µs | 0.119 µs | 불리언이 여전히 우세 (1.6배) |
| 10개 | 0.122 µs | 0.119 µs | 거의 동등 |
| 20개 | 0.219 µs | 0.124 µs | next가 1.8배 빠름 |
| 30개 | 0.312 µs | 0.120 µs | next가 2.6배 빠름 |
분기 3개짜리 일반적인 코딩 테스트 문제에서
next + generator가 4.3배 느렸다.
격차가 줄어들기 시작하는 지점은 5~10개 분기 부근이며,
10개를 넘어가면서부터 next()가 우세해진다.
하지만 역설적이게도 분기가 10개 이상이면
next() 순차 탐색보다는 이진 탐색(bisect)이나 딕셔너리 같은
다른 구조를 고려하는 게 더 유리할 수 있다.
실제로 측정해보면?
| 분기 수 | next() | bisect | dict | 결과 |
|---|---|---|---|---|
| 10개 | 0.027s | 0.005s | 0.006s | bisect가 5.4배 빠름 |
| 20개 | 0.027s | 0.006s | 0.006s | bisect가 4.5배 빠름 |
| 30개 | 0.031s | 0.006s | 0.007s | bisect가 5배 빠름 |
| 50개 | 0.049s | 0.006s | 0.007s | bisect가 8.3배 빠름 |
즉, next()가 boolean보다 빨라지는 구간(10개 이상)은 이미 bisect나 dict를 써야 하는 구간이다. '비교를 덜 하는' 최적화가 오히려 더 느린 것이다.
그렇다면 short-circuit은 파이썬에서 항상 비효율적인가?
앞에서 본 것처럼 'short-circuit을 만들기 위해 고수준 추상화를 끌어오는 경우'는 비효율적이다.
하지만 파이썬에서 short-circuit이 자연스럽게, 그리고 실제로 효율적인 경우도 있다.
다음은 내가 실제로 모 회사의 코딩테스트에 제출했던 코드의 일부다.
for other_start, other_end in self.events.values():
if not (end_min <= other_start or start_min >= other_end):
return None
이 코드는 일정이 겹치는지를 판단하는 로직이다.
end_min <= other_start-> 새 이벤트가 기존 이벤트보다 완전히 앞에서 끝나는 경우start_min >= other_end-> 새 이벤트가 기존 이벤트보다 완전히 뒤에서 시작하는 경우
이 둘 중 하나라도 만족하면 겹치지 않는다. 둘 다 만족하면 겹친다.
왜 이 short-circuit은 실제로 효율적인가?
여기서 사용한 or은 파이썬 언어 차원에서 제공하는 단락 평가(short-circuit evaluation)다.
- 왼쪽 조건이 True면 오른쪽은 평가하지 않는다
- 제너레이터 없음
- 프레임 생성 없음
- 추가 오버헤드 없음
즉, 아무것도 희생하지 않고 조건 평가를 줄인다. 앞에서 다룬 next + generator 방식과는 성격이 완전히 다르다.
이 사례가 말해주는 결론은
1. 파이썬에서 문제가 되는 건 short-circuit 그 자체가 아니다
2. short-circuit을 '구현하기 위해' 고수준 추상화를 끼워넣는 순간이 문제다
3. and나 or 같은 언어 차원의 단락 평가는 자연스럽고 손해가 없다
'마법'의 배후 : 파이썬이 숨긴 비용
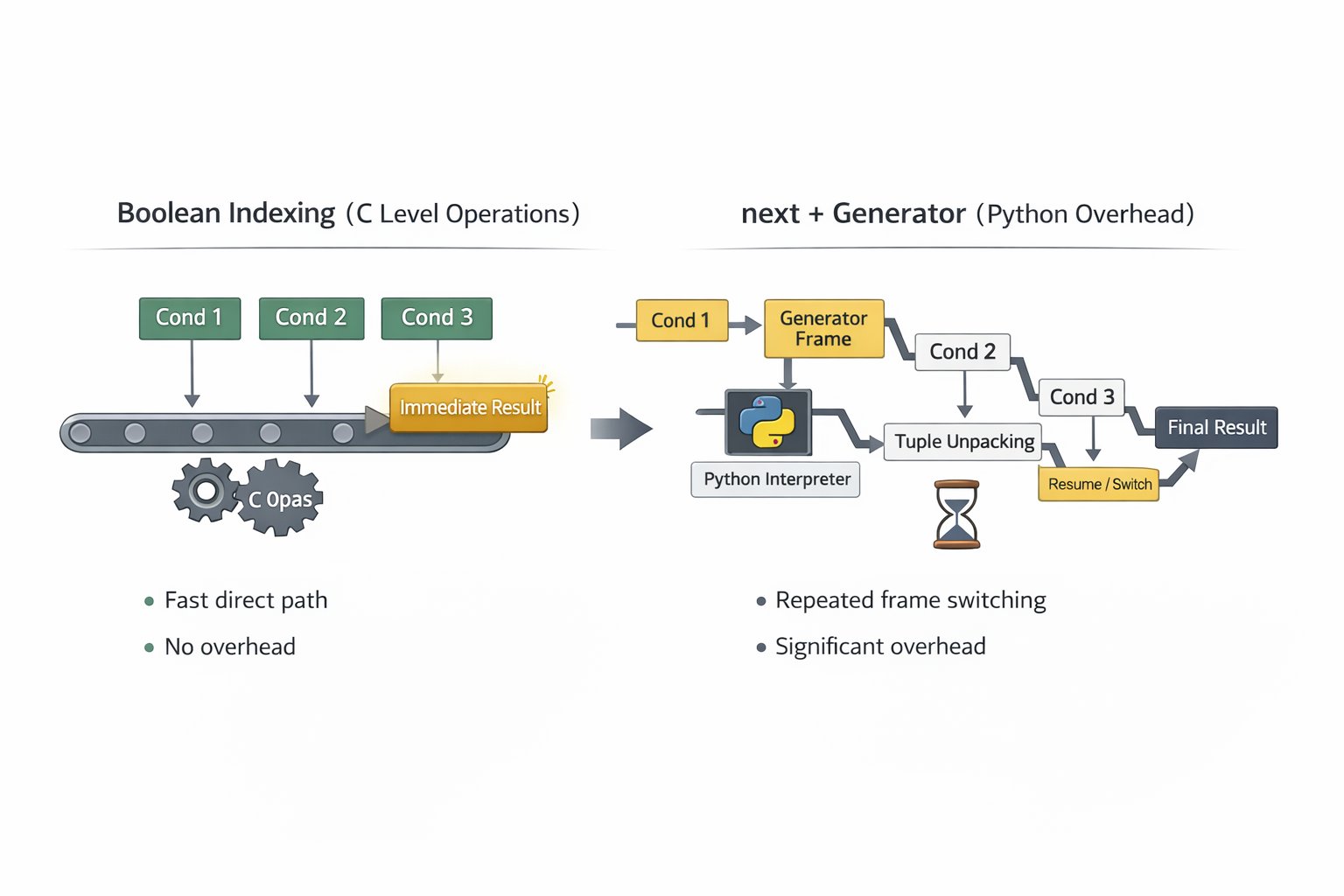
next + generator는 왜 느린가?
나는 지금까지 데이터를 순회하거나 리스트를 생성할 때, for문보다는 컴프리헨션, 컴프리헨션보다는 제너레이터가 효율적이라고 배웠고, 별 다른 의심을 하지 않았다.
특히 '코딩 테스트'라는 결과를 한번 return 하고 재사용할 필요가 없는 환경이라면 더더욱 제너레이터는 마치 '마법'과도 같은 존재라고 굳게 믿고 있었다.
하지만 '효율'이라는 단어의 주어를 확인하지 않은 게 문제였다. 제너레이터가 효율적인 건 메모리지, 속도가 아니었다.
내가 '비교 횟수를 줄여서 똑똑하게 짰다'고 뿌듯해하던 그 순간 실제로는 뒤에서 이런 일이 일어나고 있었다.
1. 제너레이터 객체 생성
2. 제너레이터 프레임 생성 및 유지
3. next() 호출
4. 이터레이터 프로토콜 진입(C <-> Python 경계)
5. 튜플 접근 및 언패킹
6. 조건식 평가(동적 타입 체크 포함)
7. 조건 실패 시 제너레이터 재개(resume)
8. 프레임 suspend/resume 반복
즉, 비교 몇 번을 줄이기 위해 파이썬 레벨 오버헤드를 대량으로 추가하고 있었던 것이다.
반면 Boolean 인덱싱은?
비교 자체는 끝까지 하지만, 이 경로의 대부분이 C 레벨 단순 연산인 직선 경로라는 것이다.
- 프레임 생성 없음
- 경계 왕복 없음
- 제너레이터 오버헤드 없음
- 파이썬 인터프리터 개입 최소화
'그냥 된다'의 진실
result = next(generator)
한 줄. 간단하고도 직관적이다.
나는 '한 줄'을 썼지만, 파이썬은 보이지 않는 곳에서 수십 단계를 실행했다.
그리고 나는 그걸 1년 반 동안 몰랐다.
왜 몰랐는가?
파이썬의 설계 철학
"Python is designed to be easy to learn and easy to read."
ー Guido van Rossum
여기 숨겨진 의미
easy to learn = 복잡도를 숨긴다
easy to read = 비용을 숨긴다
허나 오해하지 말아야 할 부분이 있다.
이건 버그가 아니라 의도된 부분이라는 점이다.
파이썬은 의도적으로
- 포인터를 숨겼다
- 메모리 관리를 숨겼다
- 타입 체크를 숨겼다
- 프레임 관리를 숨겼다
- 그 비용을 숨겼다
왜?
당신이 몰라도 되게 하려고
이게 처음에 언급했던 '독'의 정체다
초보 시절
x = [1, 2, 3]
for item in x:
print(item)
'그냥 된다' -> 좋다. 배우기 쉽다.
외계어 같은 저급 언어와 달리 고급 언어라 자연어랑 비슷하기도 하고 내가 원리를 이해할 필요도 없다.
현재
result = next(complex_generator)
'되긴 하는데 왜 느리지?' -> 독이 발현되는 순간
독의 정체는 바로 '비용을 모르는 채 의사결정을 내리는 상태' 그 자체다.
나는
- 코드를 작성했다
- 실행했다
- 결과를 얻었다.
하지만 그 과정에서
- 얼마나 많은 프레임이 생성되었는지
- 얼마나 많은 경계를 넘었는지
- 얼마나 많은 오버헤드가 쌓였는지
전혀 몰랐고, 관심조차 없었다.
내가 놓치고 있던 것
파이썬이 한 말
"나는 쉽고, 문법도 자연어와 비슷하고, 빠르게 배울 수 있어."
이건 거짓말이 아니다. 사실이다.
다만
"그 대신 성능을 포기해야 해."
"CPython이 너 대신 일할 거야."
"언젠간 청구서가 올 거야."
이게 파이썬이 하지 않은 말이다.
엄밀히 말하면 파이썬은 내가 묻지 않았기에 말하지 않았을 뿐, 기만의 의도가 있었던 건 아니다.
비유를 하자면 난 그냥 미모에 홀린 걸지도 모르겠다.
int* ptr = malloc(sizeof(int) * 100);
if (ptr == NULL) {
}
for(int i = 0; i < 100; i++) {
ptr[i] = i;
}
free(ptr);
농담이 아니고 지금 봐도 무섭다.
numbers = [i for i in range(100)]
이런데 어떻게 사랑하지 않을 수가 있을까?
"생각보다 쉬운데?"
"코드 생긴 게 쌈@뽕한데?"
"이게 옳게 된 프로그래밍이지!"
허나, 지금 정신을 차리고 계약서를 다시 읽어보니
1페이지
Python
1. 쉽습니다.
2. 읽기 쉽습니다.
3. 생산성이 높습니다.
4. 빠르게 배울 수 있습니다.
...
한 18페이지 쯤
- 본 언어는 다음 비용을 청구할 수 있습니다.
1. 인터프리터 오버헤드
2. 동적 타입 체크 비용
3. 제너레이터 프레임 관리 비용
4. C <-> Python 경계 왕복 비용
5. 메모리 관리 추상화 비용
...
- 청구 시기는 통보 없이 도래할 수 있습니다.
- 본 비용은 사용자가 인지하지 못하는 상태에서도 계속 청구됩니다.

나는 첫 페이지와 파이썬의 미모만 보고 사인을 했다.
18페이지는 읽을 생각조차 없었다.
계약서를 끝까지 읽고 나서야 깨달았다.
이렇게까지 파고들어야만 추상화 뒤를 볼 수 있다는 건,
역설적으로 그 추상화가 엄청나게 견고하게 설계되었다는 뜻이 아닐까?
나는 1년 반 동안 그 혜택을 받았다.
- 포인터 걱정 없이 코드를 짰고
- 메모리 관리 없이 결과를 얻었고
- 복잡도 고민없이 빠른 배움을 했다
파이썬은 의도적으로 이렇게 설계된 언어였다.
- 초보자가 쉽게 시작할 수 있게
- 복잡도에 압도되지 않게
- 하지만 필요하면 파고들 수 있게
그리고 그 설계를 30년간 유지했다.
파이썬은 날 속이지 않았다.
내가 계약서를 끝까지 읽지 않았을 뿐이다.
추상화의 법칙
Joel Spolsky는 이렇게 말했다.
"All non-trivial abstractions, to some degree, are leaky."
모든 비자명한 추상화는 어느 정도 새어나온다.
새는 추상화는 무조건 나쁜건가?
아니다.
- 추상화가 전혀 없다 -> 배우기 어렵고 생산성이 낮다.
- 추상화가 있다 -> 대부분의 상황에서 엄청난 생산성을 가진다.
단, 경계 영역(성능, 정확한 자원통제 등)으로 들어가면 '숨겨둔 내부'를 결국 이해해야하며, 이는 실패가 아닌 대가(trade-off)의 자연스러운 결과다.
다만 이는 파이썬에 국한된 이야기가 아니다.
예를 들면
React
- 주는 것 : 선언적 UI, 컴포넌트 재사용
- 숨기는 것 : Virtual DOM 오버헤드, 재렌더링 비용
Docker
- 주는 것 : 환경 격리, 배포 편의성
- 숨기는 것 : 네트워크 오버헤드, 이미지 크기
즉, 모든 추상화는 공짜가 아니다.
비용을 이해하고, 트레이드 오프를 파악하고, 상황에 맞게 선택하는 것
이 모든 게 엔지니어링이라고 생각한다.
파이썬이 이번에 내게 가르쳐준 건 단순히 '파이썬이 느리다'가 아니라
'모든 기술은 무언가를 숨긴다'는 것이다.
결론
파이썬으로 프로그래밍을 입문했을 때
'입문용으로는 좋지만 독이 될 수 있다'는 말을 들었다.
이제는 그 의미를 알 것 같다.
독은 이것이었다.
- 비용을 모르는 상태
- 추상화 뒤를 보지 못하는 상태
- 선택할 수 없는 상태
다만 이를 뒤집는다면
- 비용을 알고
- 추상화를 이해하며
- 의식적으로 선택한다
반대로 약이 될 수 있다는 것도 깨달았다.
파이썬은 여전히 좋은 언어다.
단지 이제는 언제, 왜 사용해야 하는지 조금은 감이 올 것만도 같다.
그래서 궁금해졌다.
추상화를 최소화한 언어는 어떤 모습일까?
다음은 Rust를 Python과 병행하여 공부하기로 했다.
파이썬이 숨긴 것들을 Rust는 드러내기 때문이다.
- Ownership
- Borrowing
- Lifetime
- Zero-cost abstractions
더 어렵겠지만,
'왜'를 더 깊이 이해할 수 있을 것 같다.
독을 경험했으니 이제 약을 만들러 갈 차례다.